树哈希
引入
树哈希的初始目的是为了判断两棵有根树是否同构,比如如下图:
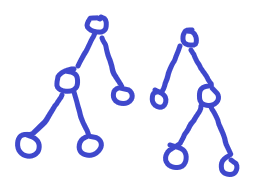
这两棵树就是同构的。 为了达到检测同构的目的,我们设计的 hash 函数应当能够对同构的子树输出相同的值。因而我们需要想出一种构造办法,能够满足得到的 hash 值不取决于便利子树的顺序。
我们设计一个映射函数 \(f(x)\) 能够把任意一个整数近乎随机的固定映射到另一个值。
然后我们设计 hash 函数 \(hash(x)=C+\sum_{u\in son_x} f(hash(u))\) (这里 \(C\) 为一个随机常量),此时我们发现这个函数正好能够满足不同的子树 hash 值不同,相同子树 hash 值相同的要求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
换根操作
这个其实就是一个换根DP的事情, 我们现在已经获得的每一个子树的 hash函数 , 假设此时我们知道了 \(fa_x\) 为根时的 hash 值, 那么此时以 \(x\) 为根的 hash 值为 \(x\) 在原子树上的 hash 值减去 \(fa_x\) 为根时除去 \(x\) 这个子树 的 hash 值, 直接给出代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |