DFS 序与树链剖分
备注
先感谢以前自己居然写了总结,I love char
但是,什么垃圾 latex
DFS 序
DFS 序,就是对于一个图进行 DFS 便利时,访问节点的顺序\ 如下图:
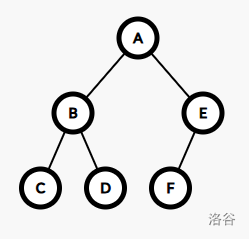
这棵树的 DFS 序是 A B C D E F
那这又有什么用呢?
当我们要计算以 B 为根的字数点权和时,相当于是求 A+B+C, 这样正好在 DFS 序中构成了一个区间。
如 [dfn[x],dfn[x]+siz[x]-1], 相当于将 树上便利 变为了 区间修改,于是可以使用数据结构来维护。
树链剖分
对于一个要进行树链剖分的树,有以下定义:
- 重子节点:儿子中子树最大的节点
- 轻子节点:其他节点
- 重边:向下连接到重子节点的边
- 轻边:其他边
- 重链:由重边相连组成的链
(如下图)
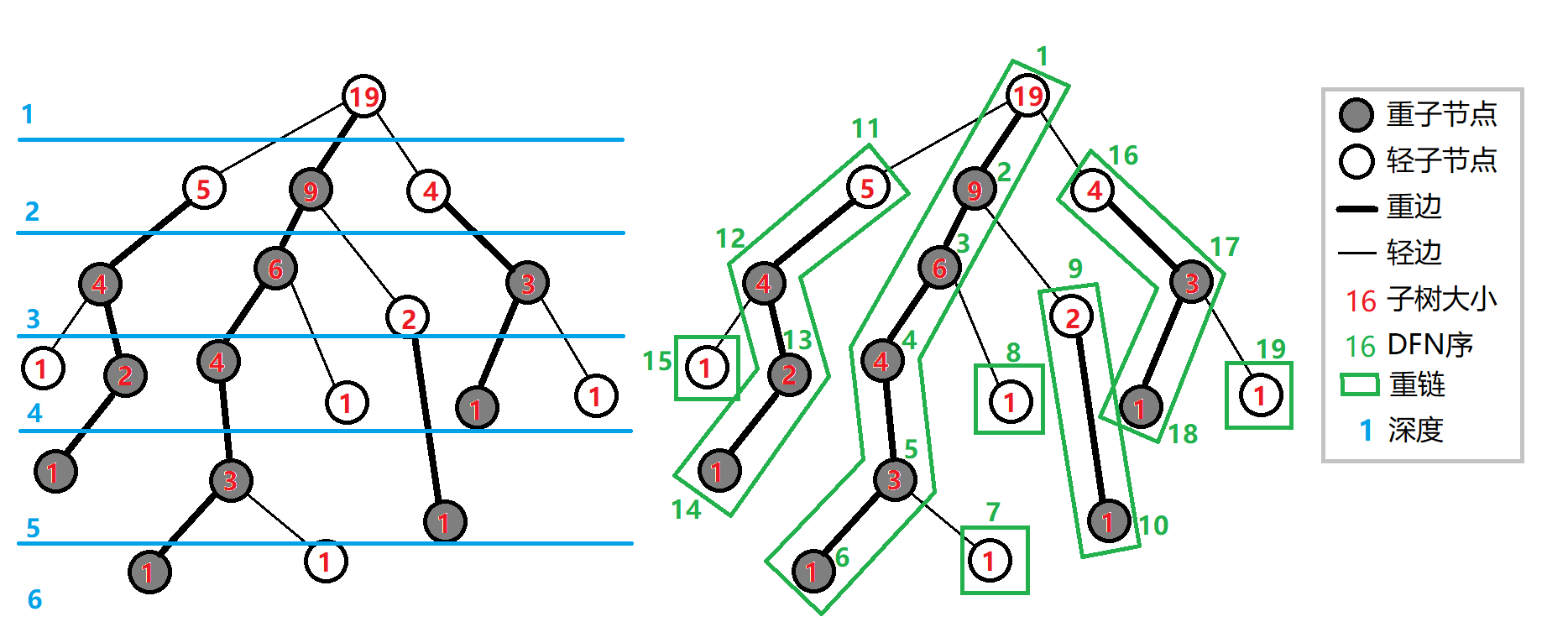
因而我们需要记录以下信息:
fa[x]父亲节点dep[x]深度siz[x]子树大小son[x]重儿子top[x]所在重链的顶部节点dfn[x]DFS 序
很明显而发现,每一个点都会属于一个重链,或者说,整棵树被分成了若干条链
更明显 能发现,轻子节点的子树大小小于父亲节点子树大小的一半
同时也 显然,任意一条最短路径可以被分成了至多 \(\log n\) 条重链
证明
我们可以将这条链分为按 LCA 分界的两条链,设这条链会被分成 \(k\) 段,则这条链上一定有 \(k\) 个轻节点,有上一个结论:轻子节点的子树大小小于父亲节点子树大小的一半 可以发现,这条链的尾部节点子树大小最多为 \(\frac{lca 子树大小}{2^k}\),lca 子树大小最多为 \(n\),且这条链的尾部节点子树大小最少为 \(1\),因而 \(2^k\) 最大为 \(n\),因而 \(k<\log n\)
那这又有什么用呢?
如果我们要求解一条路径的点权和,便可以转换为求解若干条重链,我们发现一个节点只有一个重子节点,因而只需要每一次先枚举重子节点,便可保证每条重链的 DFS 序是连续的,即可用 \(\log n\) 的时间复杂度求解每一条重链的点权和。
那么如何拆分重链
这种过程有点类似 LCA,但是每一次是从 \(x\) 跳到 fa[top[x]], 且结束条件为两点在同一重链上,步骤:
- 检测两个点的
top是否相等,如果是,跳出循环 - 如果
top[x]的深度小于top[y]的深度,交换,及每一次跳矮的。 - 对于从线段树
[dfn[x],dfn[fa[top[x]]]寻找答案 - 更新 \(x\) 为
fa[top[x]] - 回到 1
- 处理线段树
[dfn[x],dfn[y]]
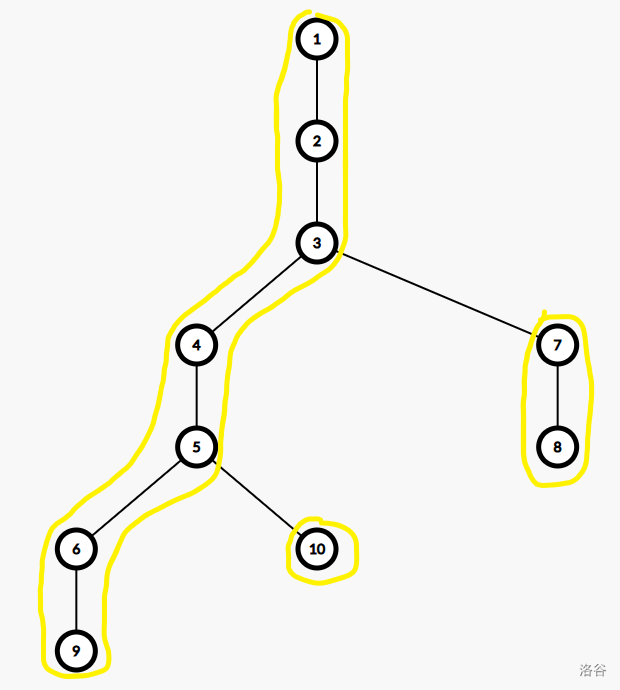
如图,当求 (10,8) 时,10 --> 5,8 -> 3 然后算 [5,3]。
CODE
DFS 预处理:
-
build1:
fa[],dep[],siz[],son[]。 -
build2:
top[],dfn[]。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
从 x 到 y 结点最短路径上所有节点的值都加上 z
CODE
1 2 3 4 5 6 7 8 9 10 | |
求树从 x 到 y 结点最短路径上所有节点的值之和
CODE
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
将以 x 为根节点的子树内所有节点值都加上 z
CODE
1 2 3 | |
求以 x 为根节点的子树内所有节点值之和
CODE
1 2 3 | |
完整 CODE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | |